Desktop Studio for Dataset Curation & Fine-Tuning
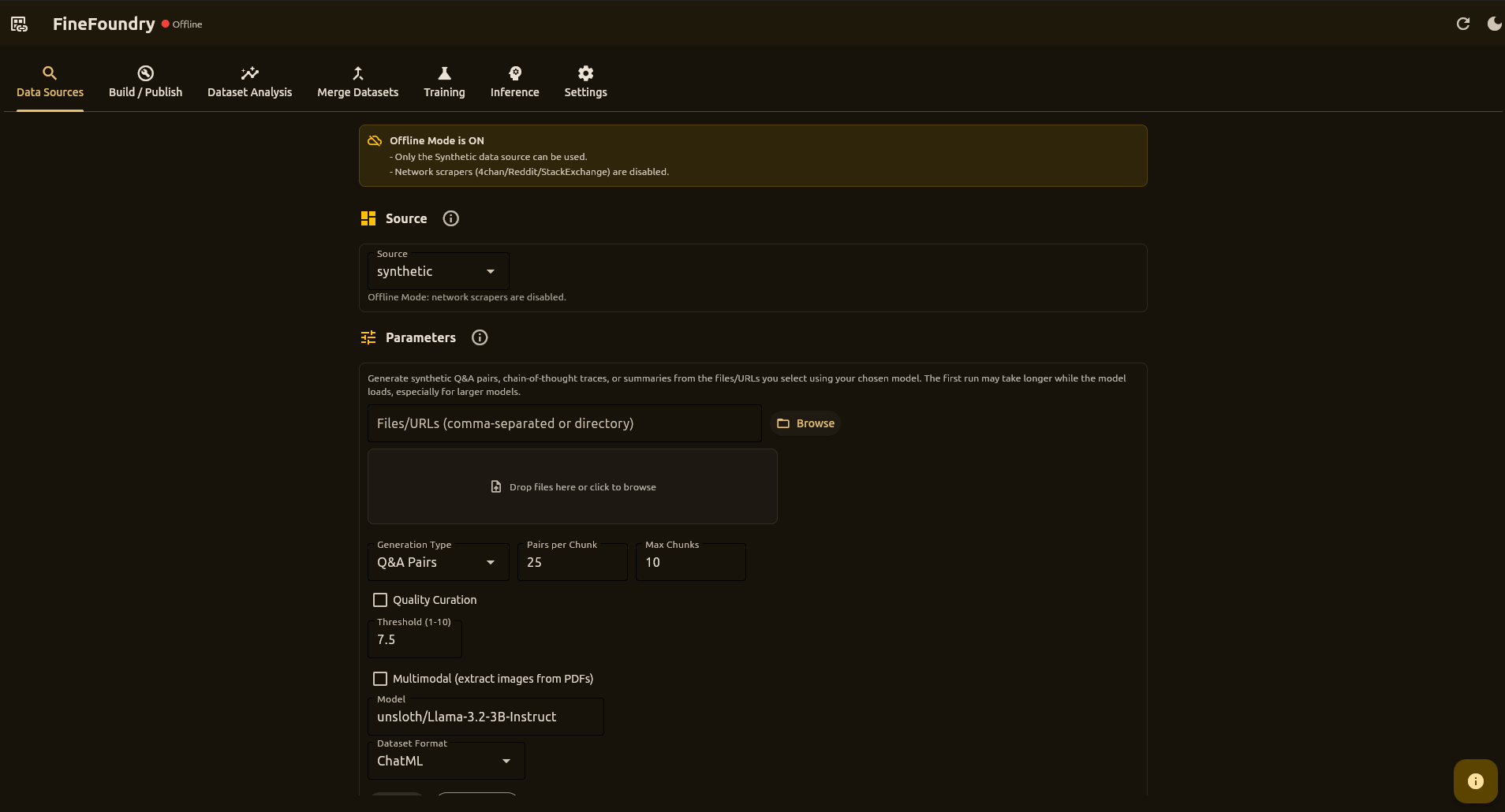
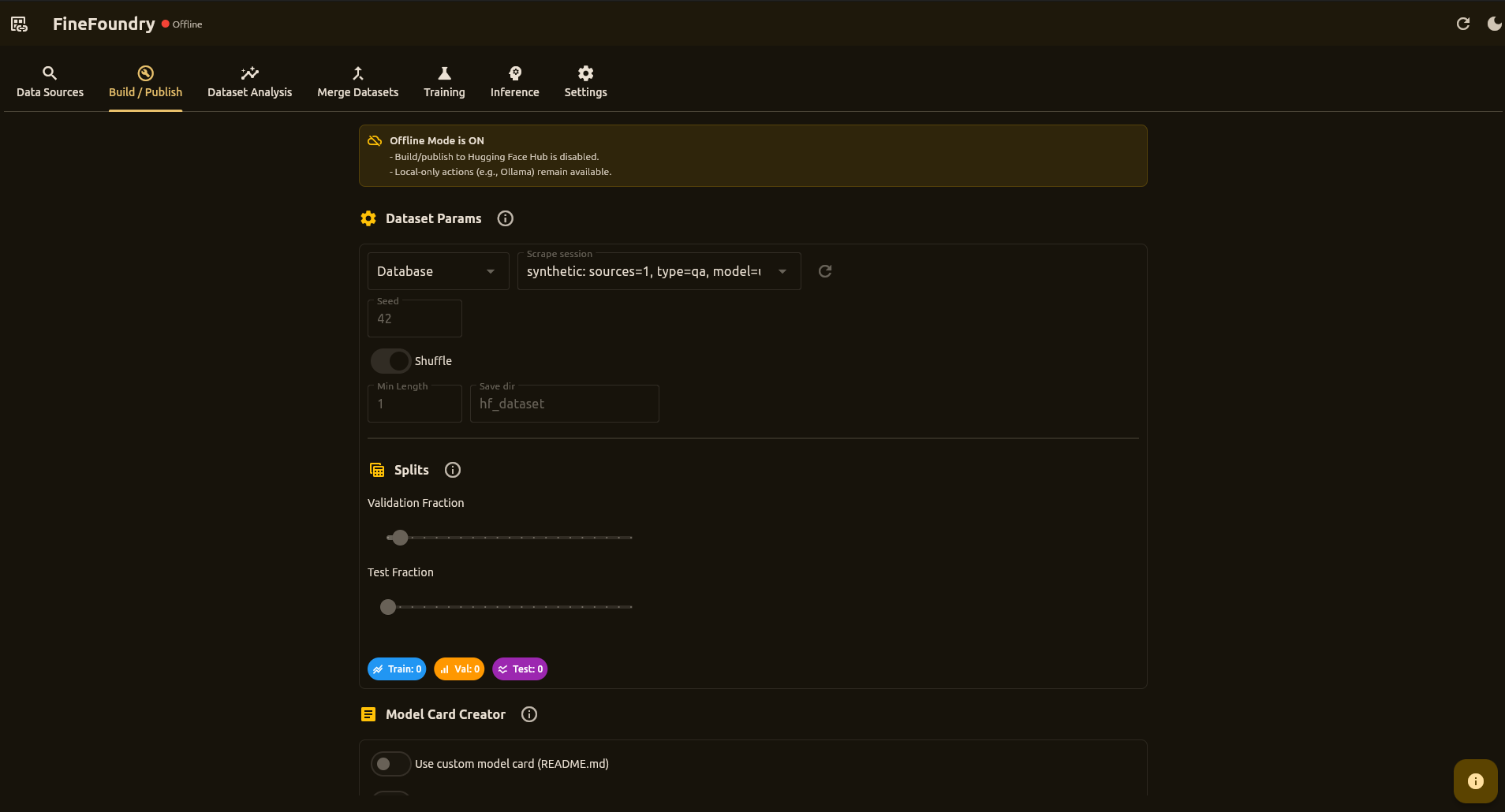
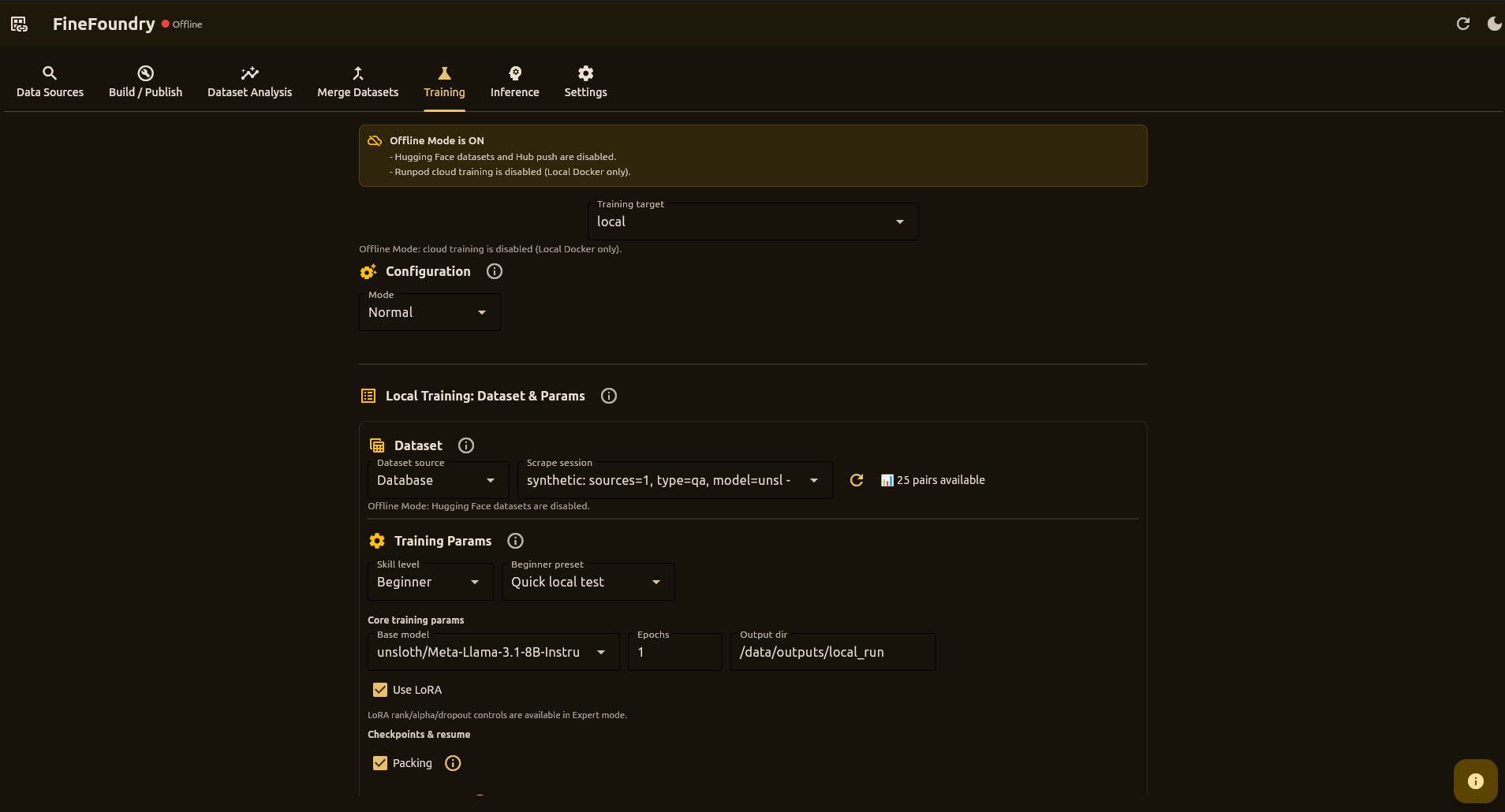
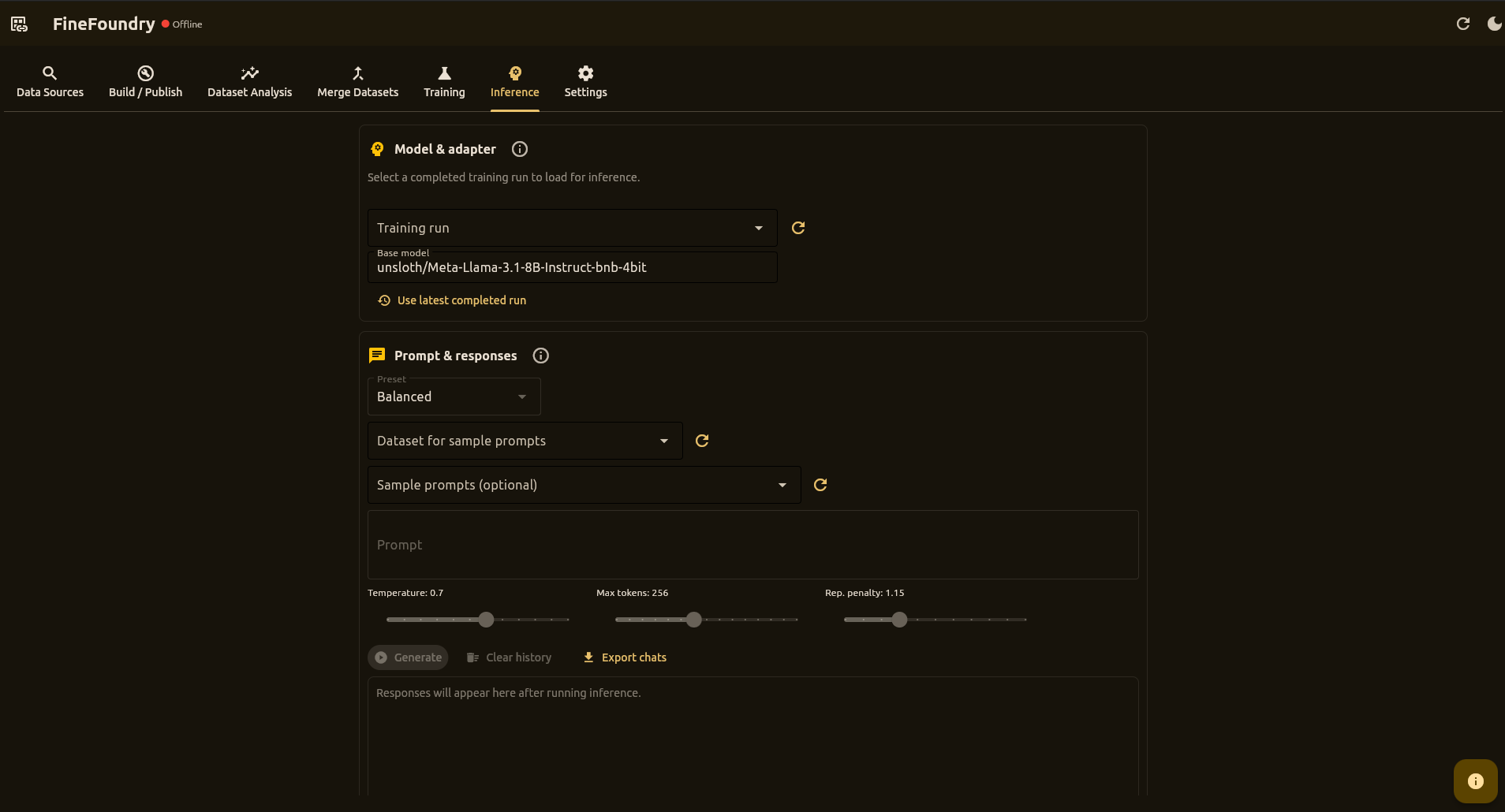
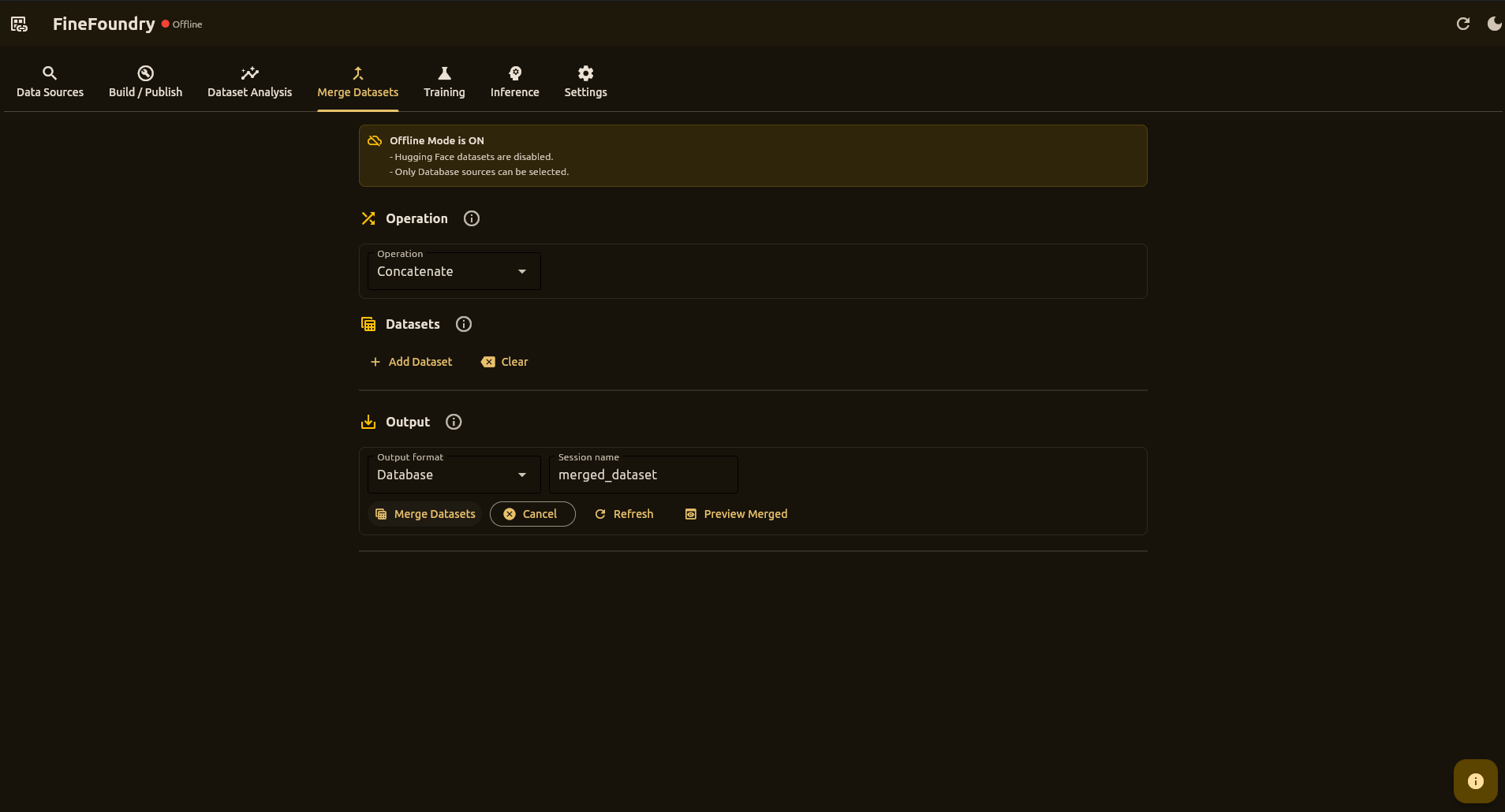
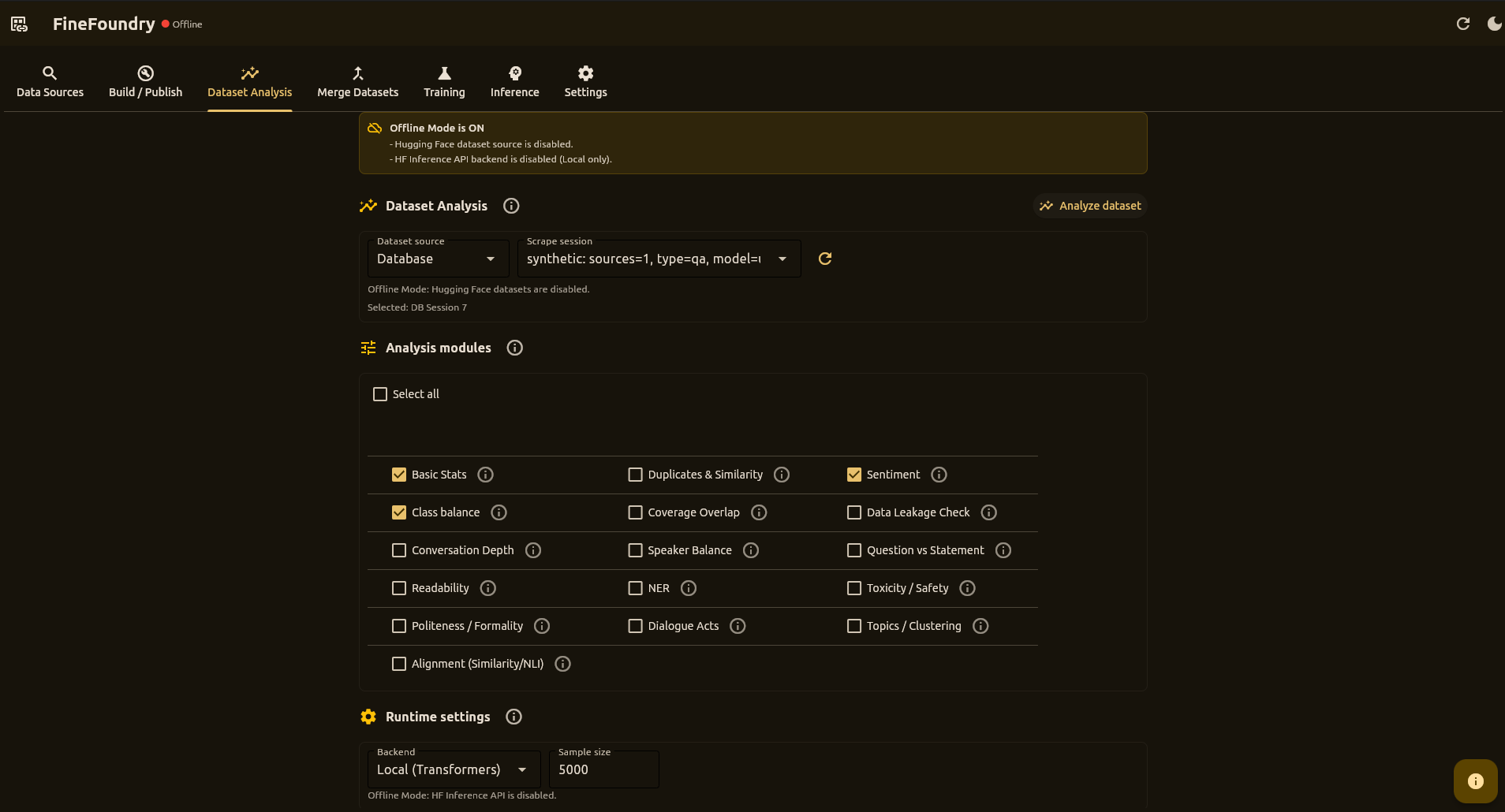
A powerful desktop application to scrape, generate synthetic data from documents, merge, analyze, build datasets, and fine-tune models with an Unsloth-based LoRA training stack. Train on RunPod or locally, run fully local inference, then ship to Hugging Face Hub.